
像放射科专家一样思考:破解通用医疗AI“贪多嚼不烂”的魔咒
在现代医学的诊疗流程中,有一项看似枯燥却至关重要的工作——医疗影像分割。无论是精准勾勒出肝脏上的微小肿瘤,还是在错综复杂的脑部扫描中区分出核心病灶与水肿区域,这项技术都是放射科医生进行疾病诊断、制定手术方案以及评估预后的基石。想象一下,如果医生能在几秒钟内获得一份高精度的器官或病灶轮廓图,这将为抢救生命争取多少宝贵的时间。
近年来,随着人工智能(AI)的爆发式增长,以U-Net为代表的深度学习模型在特定任务上已经展现出了媲美甚至超越人类专家的能力。然而,这些传统的AI模型往往像是一个个“偏科生”:擅长分割肺结节的模型可能对肝脏肿瘤束手无策,精通CT图像的模型面对MRI扫描可能就“两眼一抹黑”。这种“一任务一模型”的范式,不仅训练成本高昂,在面对纷繁复杂的临床真实场景时也显得捉襟见肘。
1. 通用模型的“成长的烦恼”
为了打破这种局限,科学界将目光投向了视觉基础模型(Vision Foundation Models)。这类模型(如大名鼎鼎的Segment Anything Model, SAM)试图通过在海量数据上进行预训练,习得一种“通用”的分割能力,梦想着“一招鲜,吃遍天”。
然而,理想很丰满,现实却很骨感。
当研究人员简单地将这些通用模型应用于医疗领域,或者将各种来源杂乱的医疗数据一股脑地喂给模型时,意想不到的问题出现了。医疗影像内部存在着巨大的差异性和复杂性,不加区分地混合训练往往会导致“负迁移”(Negative Transfer)现象——模型在学习新任务时,反而遗忘了旧任务的知识,或者因为无关信息的干扰而导致性能退化。更糟糕的是,当这些模型面对训练数据中未曾见过的医院设备(跨站点)或罕见病灶(跨任务)时,其表现往往大打折扣,这就是所谓的分布外(OOD)泛化能力差。
这就好比强行让一个学生同时死记硬背几百本不同专业的书,却不教他如何构建知识体系,结果不仅没培养出通才,反而让他连最基础的问题都答混了。如何在保持“博学”的同时,又能像专家一样精准地调用特定知识,成为了通用医疗AI亟待解决的核心科学问题。
2. MedSegX:为AI植入“知识树”
针对上述困境,来自北京邮电大学和北京大学的研究团队提出了一项开创性的解决方案——通用医疗分割模型 MedSegX。他们不仅构建了一个前所未有的结构化数据库,还设计了一种模仿专家思维的动态网络架构,成功让AI学会了在不同场景下“因地制宜”。
2.1 MedSegDB:不仅仅是数据大,更是懂“规矩”
想要训练出好模型,首先得有高质量的“教材”。研究团队耗费心血构建了 MedSegDB,这是一个基于树状层级结构组织的公开数据库。如图[1]a所示,MedSegDB 汇集了来自129个公共数据集和5个内部数据集的超过160万对图像-掩膜(image-mask pairs)。
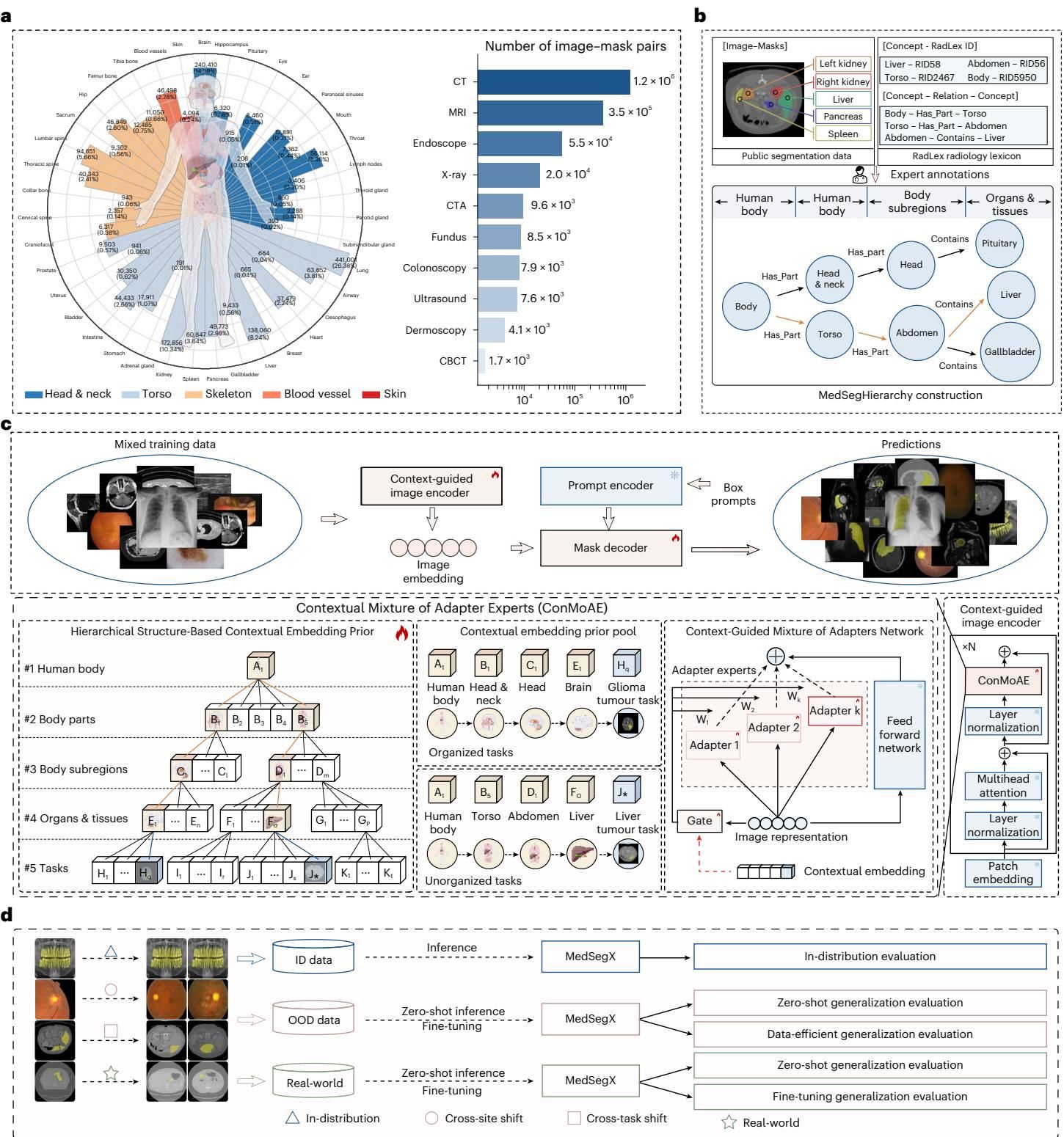
但这不仅仅是数据的堆砌。为了解决以往数据集中标签混乱、标准不一的问题(比如有的数据集将“肝脏”视为一个整体,有的则细分为“肝脏”和“肿瘤”),研究团队引入了标准的放射学术语集(RadLex),构建了一个名为 MedSegHierarchy 的解剖学层级树(图[1]b)。
在这个“知识树”中,从人体整体到头部、躯干等身体部位,再到具体的器官和组织,所有数据都被井井有条地归纳在相应的节点下。这种结构化的组织方式,让模型能够理解数据之间的语义关系——比如“肝脏”属于“腹部”,“胶质瘤”属于“脑部”。这为后续的模型训练提供了关键的上下文信息,奠定了消除“负迁移”的基础。
2.2 ConMoAE:像全科医生一样调度“专家组”
拥有了结构化的数据后,MedSegX 的核心杀手锏在于其独特的架构——上下文适配器专家混合网络(ConMoAE,Contextual Mixture of Adapter Experts)。
传统的通用模型往往试图用一套参数解决所有问题,这容易导致不同任务间的冲突。而 MedSegX 的设计理念则更加巧妙,它模仿了人类专家的思维方式。如图[1]c所示,ConMoAE 包含两个关键组件:
- HScEP(层级结构上下文嵌入先验):它利用 MedSegHierarchy 中的知识树,将当前的分割任务映射为一个包含解剖学位置和任务类型的“上下文嵌入”。简单来说,它告诉模型:“现在的任务是分割CT图像腹部的肝脏肿瘤”。
- CMoAN(上下文引导的适配器专家混合网络):这是模型的执行端。它由多个轻量级的“适配器专家(Adapter Experts)”组成。根据 HScEP 提供的上下文信息,一个“门控网络(Gate)”会动态地决定激活哪些专家模块,并赋予它们不同的权重。
这种机制使得 MedSegX 在处理特定任务时,能够激活最相关的“专家技能包”,屏蔽无关信息的干扰。这不仅极大地缓解了多任务训练时的冲突,还有效促进了相似任务之间的“正迁移”——学会了分割左肾,对分割右肾自然也有帮助。从图[1]c的架构图中,我们可以清晰地看到这种从知识先验到动态专家调度的优雅流程。
3. 全能冠军:在已知领域的全面碾压
为了验证 MedSegX 是否真的克服了“贪多嚼不烂”的通病,研究团队对其进行了严苛的“期末考试”。首先是分布内(In-Distribution, ID)评估,这考察的是模型在包含100个不同分割任务的测试集上的表现,涵盖了全身5大部位和10种影像模态。
考试结果令人振奋。如图[2]b所示,在所有任务的平均成绩上,MedSegX 取得了0.9109 的 Dice 分数(Dice 分数越接近 1 代表重叠度越高,效果越好),显著优于目前的 SOTA 通用模型 MedSAM (0.8742) 和 SAM-Med2D (0.8406),同时也超越了专为单一任务设计的 nnU-Net 模型。这打破了“通用模型不如专家模型专精”的刻板印象。
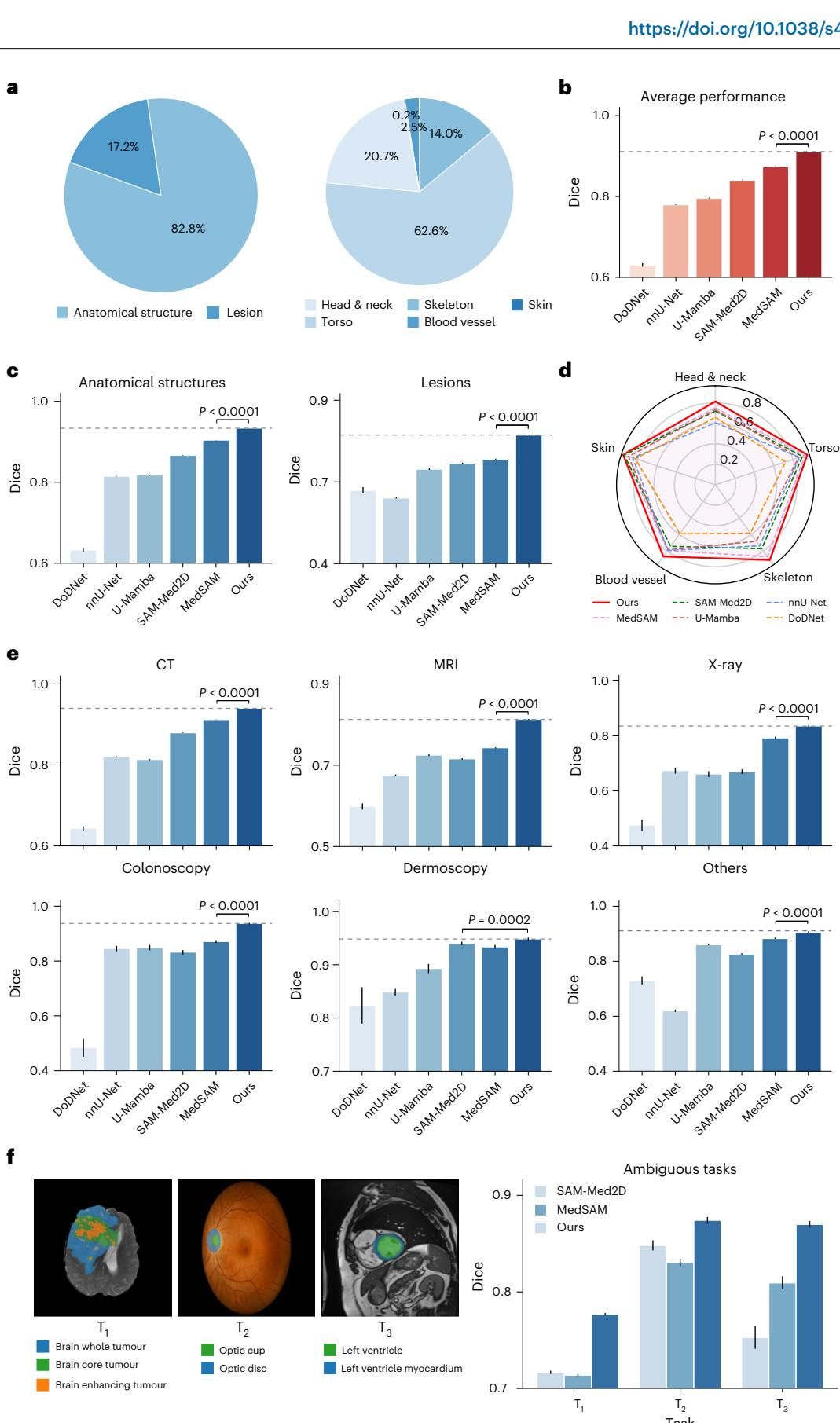
不仅是总分高,MedSegX 还是个全方位的“六边形战士”:
- 攻克疑难杂症:在相对容易的器官解剖结构分割上,MedSegX 表现优异;而在更具挑战性的病灶(Lesion)分割任务上,它的优势更为明显。如图[2]c所示,在病灶分割任务中,MedSegX 的 Dice 分数比第二名高出了惊人的 7.38%。这意味着对于形态各异、边界模糊的肿瘤,MedSegX 能看得更准。
- 覆盖全身部位:无论是结构复杂的头部与颈部,还是器官密集的躯干,亦或是细小的血管,MedSegX 在图[2]d展示的五大身体部位雷达图中,均包揽了最优表现。
- 跨越成像模态:从常见的 CT、MRI、X光,到专业的内窥镜、皮肤镜,如图[2]e所示,MedSegX 在所有10种模态上都稳居第一。特别是在 CT 和 MRI 上,它展现出了压倒性的统治力,证明了其架构能有效提取不同物理原理成像的特征。
4. 拒绝模棱两可:更“懂你”的AI
在使用基于提示(Prompt)的交互式分割模型时,临床医生常遇到一个头疼的问题——模型模糊性(Model Ambiguity)。比如,当医生在一个脑部扫描图上给出一个提示点时,他可能指的是整个肿瘤区域,也可能指的是肿瘤的核心部分,甚至是增强显示的特定区域。普通的通用模型往往会“猜错意”,给出一个似是而非的结果。
得益于 MedSegX 独特的上下文感知能力,它能更好地理解“指令”。研究团队在三个典型的模糊任务上进行了测试:脑肿瘤分层(全肿瘤/核心/增强区)、眼底视盘与视杯、左心室与其心肌壁。
结果如图[2]f所示,在这些容易产生歧义的任务中,MedSegX 展现出了极高的“情商”。例如在脑肿瘤任务中,相比于其他基于 SAM 的模型在 0.72 左右徘徊的 Dice 分数,MedSegX 一举提升到了 0.7961。在视盘和视杯的分割中,其表现更是达到了 0.91 以上。这说明,当模型“心里有数”(具备明确的任务上下文嵌入)时,它就能在复杂的重叠结构中,精准地切出医生心中想要的那个目标,极大地减少了人机交互中的误解。
5. 走出舒适区:挑战未知的勇气
如果说 ID 测试是考查模型对“课本知识”的掌握程度,那么分布外(OOD)评估就是一场没有任何复习范围的“奥数竞赛”。在真实的临床环境中,不同医院的设备参数千差万别(跨站点偏移),新的病灶类型层出不穷(跨任务偏移)。一个真正实用的医疗AI,必须具备在这些陌生场景下生存的能力。
5.1 跨越山海:不同医院间的无缝衔接
医生们常面临这样的尴尬:花大价钱买来的AI模型,在A医院用得好好的,换到B医院就不灵了。这是因为数据采集设备或病人群体的差异导致了数据分布的微妙变化。为了测试 MedSegX 的适应力,研究团队设计了跨站点(Cross-site)评估。
如图[3]a所示,这项测试涵盖了18个解剖相关的任务,但训练数据和测试数据来自完全不同的机构。例如,模型可能是在日本和美国的X光片上训练的肺部分割,测试时面对的却是来自中国的X光片数据。
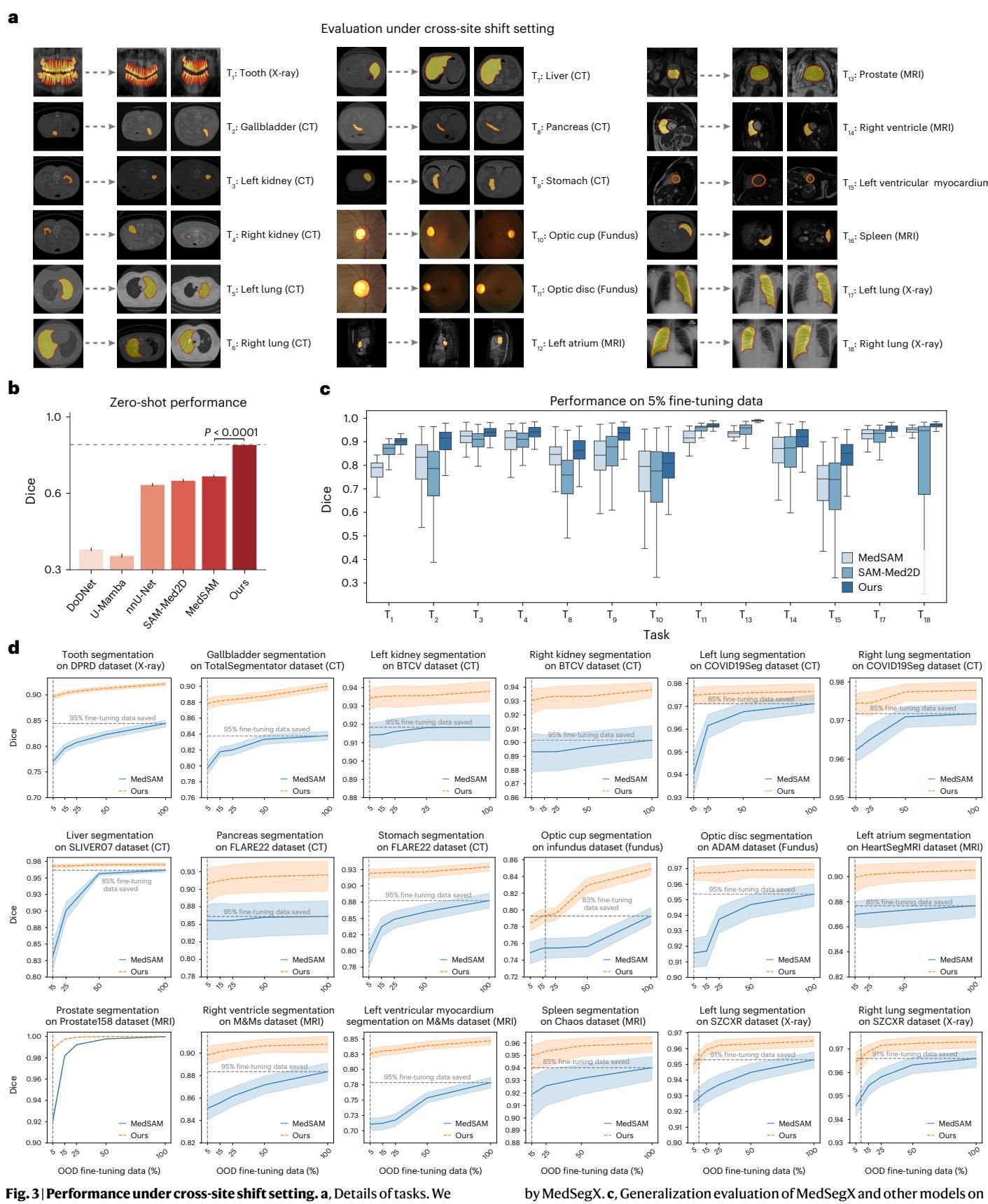
零样本(Zero-shot)表现: 即使完全不给模型看新医院的数据,直接上手实操,MedSegX 依然展现出了惊人的泛化能力。从图[3]b中可以看到,在零样本设置下,MedSegX 取得了 0.8733 的平均 Dice 分数,而同类的 MedSAM 仅为 0.7296。这意味着 MedSegX 能够凭借其学到的通用解剖学知识,克服设备差异带来的干扰。
数据高效(Data-efficient)微调: 如果允许模型在新环境里“实习”一会儿呢?结果显示,MedSegX 是一名极具天赋的“快手”。如图[3]c和[3]d所示,仅仅使用 5% 的新站点数据进行微调,MedSegX 的性能就飙升到了 0.9070,甚至超过了其他模型使用 100% 数据微调的效果。这对于标注成本极高的医疗领域来说,无疑是一个巨大的福音。
5.2 举一反三:从常见病到罕见病
更严峻的挑战在于跨任务(Cross-task)评估。研究团队选择了7种模型从未见过的肿瘤类型,包括相对常见的结肠癌、肾癌,以及罕见的前庭神经鞘瘤(如图[4]a所示)。肿瘤的形状和纹理异质性极高,分割难度远超固定形状的器官。
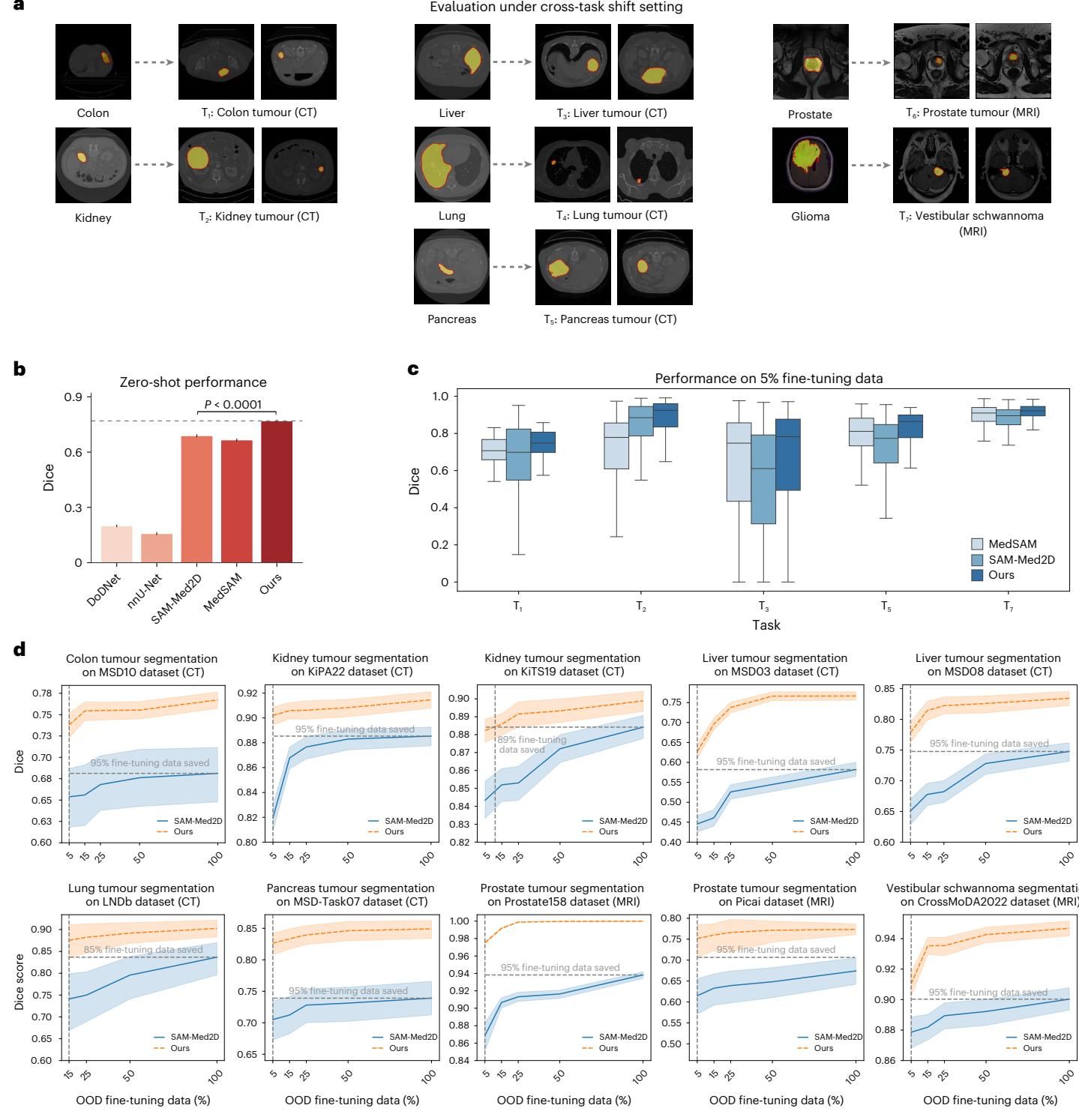
在这个“超纲题”测试中,MedSegX 再次证明了其架构的优越性。如图[4]b所示,在零样本情况下,它对这些未见过的肿瘤分割任务达到了 0.7691 的 Dice 分数,比第二名高出了整整 8.05%。这说明模型并不是死记硬背了训练集里的肿瘤样子,而是真正理解了“什么是异常病灶”。
同样,在数据效率方面,MedSegX 延续了其强势表现。如图[4]c和[4]d所示,只需极少量的样本(5%-25%)进行“点拨”,它就能迅速掌握新肿瘤的特征,达到甚至超越其他模型全量微调的水平。这种“举一反三”的能力,得益于 ConMoAE 架构能够从已有的知识库中检索相似任务的先验信息(比如将肾肿瘤与已学的肾脏解剖结构联系起来),从而实现知识的正向迁移。
6. 临床实战:真金不怕火炼
为了检验 MedSegX 是否真的具备了“临床上岗”的资格,研究团队收集了来自4家不同三甲医院的5个真实世界数据集(如图[5]所示),这些数据涵盖了结肠癌、胃癌、肺癌、肝肿块以及肺炎等多种复杂的临床病症,是检验模型成色的“试金石”。
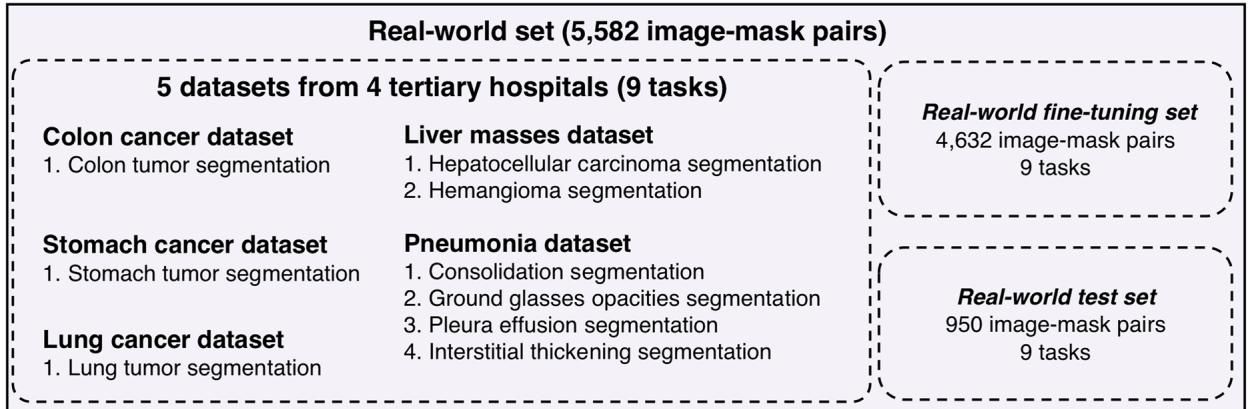
零样本“盲测”: 如图[6]a所示,在完全没有接触过这些医院私有数据的情况下,MedSegX 在所有五个数据集上的零样本表现都大幅领先于 SAM-Med2D 和 MedSAM。特别是在肝肿块分割任务上,其优势尤为显著,显示出对不同扫描设备和成像参数的极强适应性。
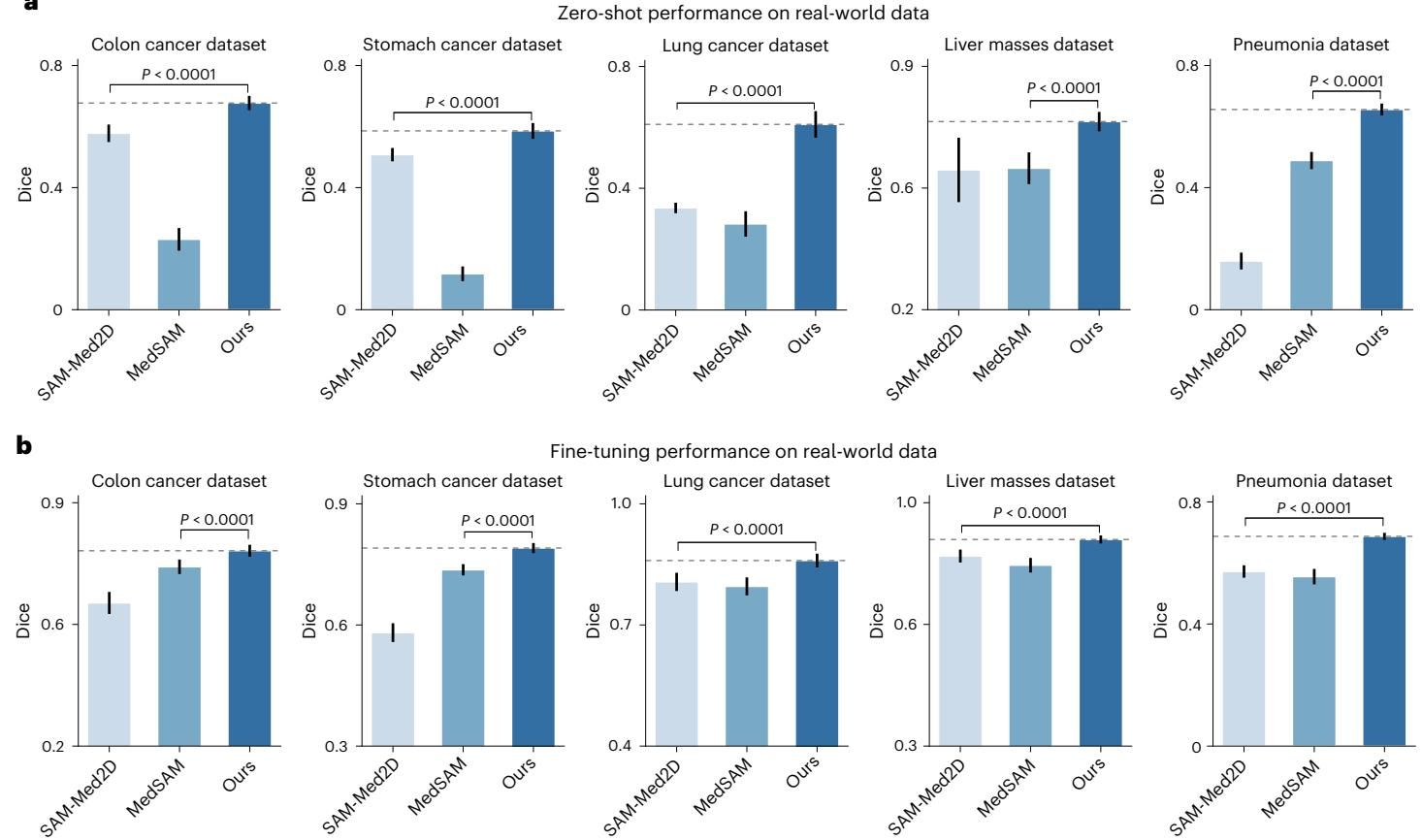
微调后的“进阶”: 当给予少量数据进行微调后(图[6]b),MedSegX 的潜力被进一步释放。值得一提的是在极具挑战性的肺炎病灶分割任务中,由于病灶通常呈弥漫性分布,边界极难界定(如磨玻璃影、实变),所有模型的表现都有所下降。然而,MedSegX 依然稳住了阵脚,以平均 11.5% 的 Dice 分数优势碾压了第二名,充分证明了其在处理复杂、模糊病理特征时的鲁棒性。
7. 进军三维:MedSegX3D 的降维打击
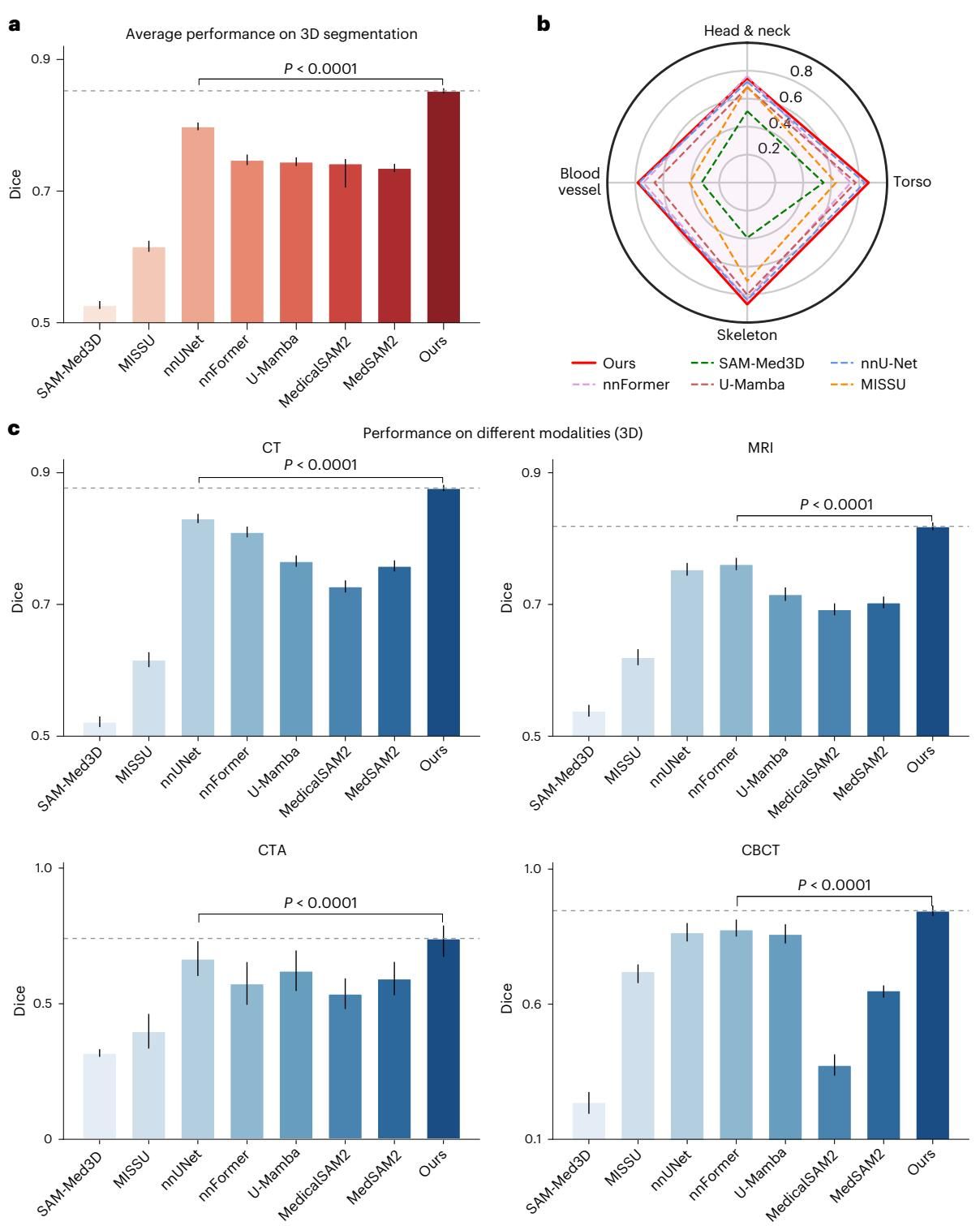
医学影像本质上大多是三维的(如CT和MRI序列)。为了进一步释放潜力,研究团队将 MedSegX 扩展为了支持体积数据的 MedSegX3D,通过引入3D适配器来提取深度维度的信息。
结果再次证明了其架构的普适性。如图[7]a所示,MedSegX3D 在3D分割任务上的平均 Dice 分数达到了 0.8523,不仅远超 SAM-Med3D (0.5270) 等通用模型,甚至击败了医学影像分割领域的“常青树”——专为3D任务设计的 3D nnU-Net (0.7983)。无论是在 CT、MRI 还是 CTA、CBCT 等模态下(图[7]c),MedSegX3D 都展现出了统治级的表现,这表明它成功地将 2D 预训练中学到的丰富语义知识迁移到了 3D 空间中,实现了对传统专用模型的“降维打击”。
论文信息
- 标题:A generalist foundation model and database for open-world medical image segmentation.
- 论文链接:https://doi.org/10.1038/s41551-025-01497-3
- 发表时间:2025-9-5
- 期刊/会议:Nature biomedical engineering
- 作者:Siqi Zhang, Qizhe Zhang, Shanghang Zhang, ..., Guangyu Wang
本文由超能文献AI辅助创作,内容仅供学术交流参考,不代表任何医学建议。
分享